A New Definition for Client/Server
| WARNING - This is a work in progress. You
are welcome to read and make comments on the draft. Please check the document's
properties for last update information.
|
"Middleware is a very misunderstood but important positioning move
for banks... Middleware will allow banks to separate business rules from access
technologies that are particular to a delivery channel and permit banks to
efficiently keep pace with rapidly changing programming languages."
Andrew DeMeo
President Electronic Commerce Marketing Systems
Bank Technology News
December 1998
Introduction
Many have been excited with the promise of Client/Server while
at the same time others have not. While one publication is touting a success
story another is proclaiming its demise. What gives? How can both be true? One
problem may be everyone doesn't have a common definition of what a
client/server design is. Even after reading the books and going to seminars
it's still unclear how some people succeed with it and others don't.
Maybe we need a new definition--one less susceptible to weak
interpretations.
First, let's agree that DB2, Sybase, and Oracle, in their latest versions,
are successful, representative client/server systems. These modern database
systems have one primary function: managing databases. One reason they're
considered client/server is their clients (our GUI applications) don't need to
include the code for manipulating the database. What are the advantages to
database vendors?
- The client-access code is smaller (fewer lines) than the database code
- The client-access code is easier to port by virtue of there being less of
it to port
- The client-access code can be more reliable by virtue their is less of it
to screw-up
- The client-access code can mature independently of the database code
- The database's (server) and the application's (client) logical address
space can be separate (using memory-to-memory IPCs)
- The server's and the client's physical address space can be separate (using
network RPCs)
- The server and client can be on different computers
- The server and client can be on different operating systems
Ultimately, these attributes translate into financial benefits:
- The database (server) can't (shouldn't) be fouled by errant applications
(clients) and so is less costly to support
- The server can be modified without requiring clients to recompile or relink
- The value of the server is increased by the number of clients that can
access it
- The value of the server is increased by the types of clients that can
access it
- Applications using the server have smaller disk and memory footprints,
requiring less expensive hardware
- Clients can focus on their responsibilities while the server focuses on its
In a generic way these attributes and benefits should exist in all
client/server systems. A common mistake application developers make is to
assume that by using some vendor's client-access code they have created a
client/server system of their own. The most prevalent example of this is a
Powerbuilder-created application (or Visual Basic, Visual Age, Delphi, doesn't
matter) that accesses a database on a back-end machine. What's been created is
another monolith. In fact, this monolith is more complicated than the monoliths
of the 60s and 70s because it's introduced network communications where before
they at least lived on the same machine!
A GUI application using a remote database engine is NOT a client/server
creation. It is merely a recreation of another database client. The new
application has no clients of its own and therefor yields none of the benefits
expected of client/server systems. To suggest such a system is client/server
would be to take credit for the database vendor's accomplishment.
Sneaking up on a new definition
Client/server systems have two important entities; clients and
servers. Having clients implies there's something useful on the server clients
wish to use. The server does something that isn't worth recreating in the
client. For example, since most programmers are uninterested in writing
database systems it makes sense to (re)use one already available. Even if we
were interested it's unproductive to write one ourselves. The time spent to
create even the simplest database system would be better spent on our new
application.
Consider the following diagram:
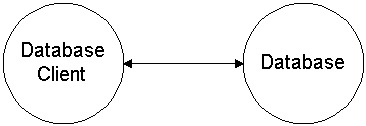
This figure represents the quintessential client/server application. Right?
What we're really looking at is the result after someone wrote a database
client. If the database client doesn't get credit for the client/server design
and the database vendor didn't write the application, where does client/server
design actually exist?
Consider a new picture:
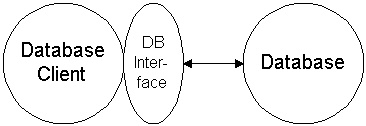
You can't take credit for the database, you only wrote your application.
Sybase, IBM, and Oracle only created their databases and their database
interfaces. What makes client/server work is the server has an interface. The
interface allows clients to access the server's resources and functionality.
Once an interface to a server exists and the server does something useful
there's no limit to the types and shapes of its clients.
2-tier, 3-tier, we all cheer for n-tier
Industry rags have found a new buzz-phrase, '3-tier.' The really
hip, feeling constrained by literals, use 'n-tier'--suggesting they already
know there's a larger world out there about which the-rest-of-us are
unfamiliar. 3-tier paradigms look something like this:
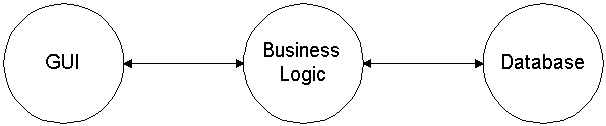
The application (what used to be the database client) has separated its
presentation (its user interface) from it's business rules. But for this to
work our business logic needs an interface in the same way as database servers:
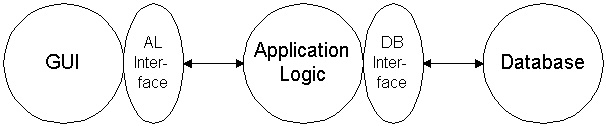
Sybase is credited with ushering-in (or at least coining the phrase) client
server when it created its database and the database interface (DB-Lib then
CT-Lib). It's important to note that what they delivered was indeed
client/server even though they didn't deliver a single database client.
We create client/server systems the same way. Not by delivering clients but
by delivering servers with server interfaces. In the figure above the utility
of client/server is realized not with the client, but with the application
logic and its interface. Once the application logic's interface is created
there's no predetermination on what the user interface will be. A well defined
application implementing only its logic and an interface could easily result
in:
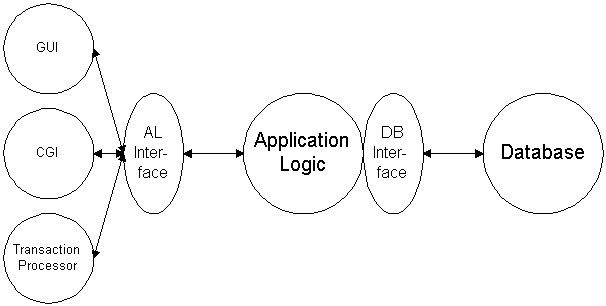
Looking at the last figure another way, what we're seeing isn't really
three-tier, but it's two two-tier systems placed end-to-end. This type of
Lego-construction (or what I call software plumbing) can be repeated as often
as useful:
Stored Procedures
Stored procedures are an instance where you can create a
client/server system without necessarily creating a server and a server
interface.
Stored procedures are SQL programs loaded into the database to facilitate
speedier execution. The execute more quickly than standard SQL because they
were precompiled when they were loaded into the database. Typically, the
language of stored procedures is SQL-based but not strictly so. Though far from
being a general-purpose language it's not strictly for table manipulation
either.
In addition to SQL, stored procedures may contain business logic. If a bank
withdrawal were implemented as a stored procedure it may include code for
checking the user's authority to withdrawal money, checking the balance of the
account, checking for overdue loans on related accounts, and updating a
transaction record for monthly statement creation. Taken independently these
tasks are simple SQL statements. Taken together they form a complex
transaction. A business transaction. Something that can be shared.
Stored procedures are a form of business logic and add value to the
database. Without them the database could do nothing in the way of banking.
Databases, and their schema do little in the way of explaining how a withdrawal
transaction is accomplished. But databases provide a functional middleware
layer by supplying a mechanism to invoke the stored procedure to clients. In
the same way databases must provide an interface to communicate SQL, they also
provide an interface to initiate stored procedures. Taken together, database
stored procedures qualify as a client/server system; there's both a service
(the stored procedures) and an interface (the database's).
Stored procedures are not without cost. When the database is busy executing
the stored procedures it's not busy doing what databases are supposed to do,
organizing and accessing data. Though stored procedures are precompiled to the
database, they are not compiled into machine code (typically, DB2 may be an
exception) and are inefficient. If transaction throughput is a priority, you're
stored procedures should stick to doing data-base related things and stay away
from extraneous business think. There are better places to do it.
Case Study #1
A software vendor that provided on-line transaction processing
systems to the credit union industry attempted to port their system from a
proprietary database to Sybase's relational database. The system had over
three-hundred tables as it approached completion (thanks to the religious
zealotry of the DBAs). All financial transactions were implemented as stored
procedures. The target TPS was a modest 11 (low by industry benchmark standards
by high considering the target hardware environment). In March, only nine
months before the first installation was scheduled the sustained throughput was
only 1.5 TPS. Database statistics indicated the simplest transaction, a share
purchase (demand deposit) required over 1500 logical IOs to complete. Multiple
posting threads didn't increase the throughput appreciably since the database
started thrashing. 1.5 TPS was all that was possible on the target equipment.
Both CPU and disk IOs were near 100% utilization. The point of diminishing
returns was too early on the curve. If they had stopped there this would have
been recorded as yet another client/server disaster. But they didn't.
Further analysis of the purchase transaction showed only 100 of the 1500 IOs
was unique. A code review of the stored procedures showed little room for
improvement since stored procedures had a limit to how many parameters could be
passed and had no way of sharing variables between them. Temporary tables were
visible only to the procedures that created them and regular tables presented a
locking problem.
It was determined the only way to create a purchase transaction that
required only 100 unique IOs was to use a general purpose language. The program
'tpserver' was created and it had a few predictable characteristics:
It read all static tables (branches, states, tellers, credit union options,
etc.) once at initialization.
It made one trip to the database to request all account-related information
per transaction.
It made one trip to the database to update all account and transaction
history information per transaction.
With the IOs reduced to a more reasonable 120, TPS more than doubled to 4.
Still not ready for production but something more interesting happened.
Database utilization (CPU and disk) fell to below 10%. This time when they
tried running 12 threads (multiple tpservers) they discovered they could
achieve 17 TPS. And it was only June!
Case Study #2
Now the software vendor had another problem. How to arbitrate
access to 12 tpservers for 200 tellers, dozens of ATM drivers and switches, and
batch posting programs? Enter poserver.
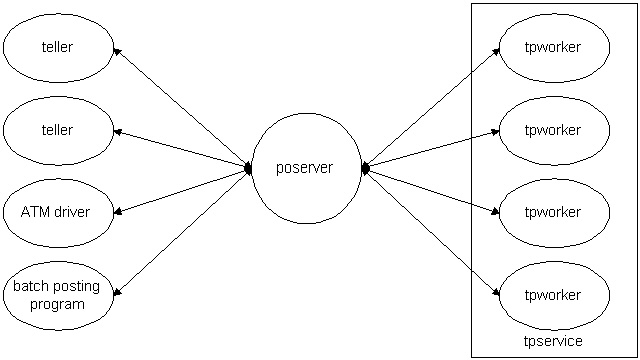
poserver lived between the tpservers and their clients. It provided a single
point of contact for clients and tpservers. This meant that wherever clients
lived on the network they only needed to locate one process, poserver, to send
all their requests to. Conversely, the tpservers appeared to only have a single
client, the poserver, which they needed to talk to.
poserver had a few very specific responsibilities. It had to:
- handle client communications, including logon, logoff, and abends
- handle worker communications, including starting, stopping, blocking, and
abends.
- keep track of which service a client requested
- keep track of which service a worker provided
- schedule client transactions for the next available worker providing the
client-requested service
poserver's most important contribution was off-loading the
client-communication responsibilities off the workers and onto itself. It
defined the workers' API to the clients, relieving the workers of even having
to do that. It enabled the workers to be client/server by providing and
managing a network-accessible interface to clients of any type.
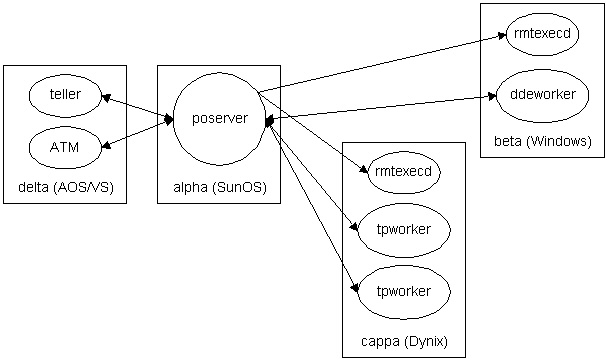
Case Study #3
poserver could have been responsible for starting the worker
processes but that would have meant workers had to be on the same machine as
poserver. To be truly scalable the system would have to support running workers
anywhere on the network available CPU existed. To do this, poserver could also
have used UNIX's rsh or rexec() to spawn the workers but that would have been
UNIX dependent. Other operating systems, though supporting Berkeley-style
sockets, may not support UNIX's rsh or rexec().
Yet another process was created called rmtexecd. It's specific
responsibility was to listen on a specific machine port for requests to start
programs, start them, and log their behavior (start time, environment,
arguments, signals, terminations). Though created initially on SunOS, rmtexecd
was easily ported to Windows, AOS/VS (Data General's 32-bit OS), and OS/2. Now
a complete mechanism was in place clients to access any service on the system
regardless of where it was on the network or what operating system it ran on.
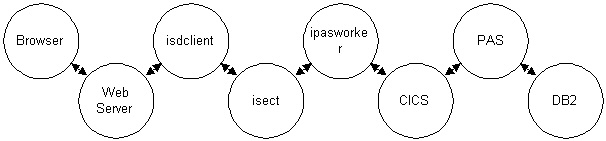
Birds of a feather
The servers in the examples (poserver, tpworker, ddeworker,
rmtexecd) have some things in common. Each server:
- does a specific task
- has value to multiple clients
- has an interface
- is reusable
rmtexecd's reuse wasn't exploited by supporting multiple and varied clients
as it was in its ability to be ported to multiple and varied operating systems.
When a program is specific in its task porting is no big deal. isdexecd's
source code has only 549 lines. It's single API function, isdexec(), has 49.
(poserver's reincarnation as isectd has only 2248!)
Each of the examples above could easily be mistaken for a three-tier
(n-tier) system, the Sesquatch of contemporary trade-rag pundit-coined
consultant-regurgitated industry buzzwords. In reality, each is only one
client/server pair stacked in front of another.
| poserver, renamed isectd, and its interface
libraries are available from Networking Technologies for Solaris, Linux, AIX,
and Windows '95 and NT.
|
Action Steps
Gartner Group is famous for observing there's a difference between where you
are and where you'd like to be. As attractive and beneficial as client/server
systems are it's troublesome C/S hasn't permeated our designs. With each new
project programmers have to ask themselves what they must do today to prepare
themselves for tomorrow. Here's some suggestions gleened from the examples:
- Divide applications into discrete tasks. Minimally, most application can be
separated into presentation and business logic
- Each division should be created in its own program
- Business logic should be designed around discrete transactions
- Rather than inventing your own network communications, use middleware like
IBM's MQSeries
- Use stored procedures to more efficiently interact with the database. Do
not use them to implement business logic.
- When designing the messages between clients and servers, keep them textual.
This eases the creation of test harnesses (you're unit testing, aren't you) and
simplyfies debugging (either in-process or postmortem).
- Keep the API simple. In DBlib, a single dbexec() command can perform any
dynamic SQL functions. MQSeries has 11 verbs. Isectd only five.
Example #1
| A more elaborate description of the
proof-of-concept is available at http://128.1.120.213/ecis/dnotes/1.shtml.
|
To export CIS to a browser we needed to create an application that lived
behind the web server that could communicate with Hogan on the mainframe. An
interface, called PAS, exists that allows programs to submit Hogan read and
write transactions via CICS. Additionally, PAS was front-ended with IBM's
MQSeries to even further simplify connectivity and extend accessibility to
machines without CICS connectivity to the mainframe.
Two programs, ipas and ipasworker, were created to test connectivity. ipas
was ment to be used interactively and accepted transaction requests from
standard input. Test files were created that could be redirected into ipas
(ipas < testfile). ipasworker was created so that the process could
establish a connection with MQ and the mainframe PAS server once and reuse it
for subsequent transactions--reducing the critical path for each transaction.
ipasworker shared all ipas' code but accepted transaction requests from isectd.
| The source code, in C, will be made available
on ATP's FTP server in the near future. If you'd like access to it before then
(like, now), contact Thomas Gagne.
|
Example #2
A large bank's Investment Mangement dept. has its own internal webserver
that integrates real-time stock quotes and news into its web pages. On nearly
any report that includes ticker symbols. Users can click
on the symbol to get a real-time quote. Additionally, this department's home
page lists several quotes for competing institutions
that are updated whenever the page is refreshed.
The realtime market data is provided by Quotron, a subsidiary of Reuters.
Both Quotron and Reuters provide data feeds with APIs. These 'elementized' data
feeds allow programs to extract and manipulate the discrete fields that make up
a quote. For instance, a quote for XXX (a fictional company) returns:
% isdclient isdquote
ALL XXX
go
RIC=XXX
LAST=65 1/4
NET=-13/16
PREVCLOSE=66 1/16
DAYHIGH=65 13/16
DAYLOW=65
DAYOPEN=65 13/16
YEARHIGH=73
YEARLOW=46 1/2
BID=65 3/16
BIDSIZE=10
ASK=65 5/16
ASKSIZE=10
VOLUME=48800
PREVOL=48800
TIME=10:45
DJTIME=00:00
RTTIME=00:00
DIVIDEND=1.28
EXDIVDATE=12/11/98
YIELD=1.9
EARNPERSHARE=3.60
PE_RATIO=18.1
The bold text is what was returned from the quote worker. isdclient is a
generic interface to isectd and any of its workers that accept plain-text
messages and return the same. ALL XXXis the transaction request
telling the worker to return everything it knows about XXX Corp.
Quotron actually provides different APIs for quotes, news headlines, and
watchlists (aka price caches). A separate program was created for each of the
interfaces, qixnews for headlines, qixquote for quote requests, qixcache for
watchlists, and qixsym for symbol lookups. All four workers accept text
requests and return text responses.
% isdclient isdcache
list(last net volume)=cma one
RIC=CMA
LAST=65.312
NET=-0.750
VOLUME=52800.000
RIC=ONE
LAST=51.000
NET=-0.562
VOLUME=426900.000
Each worker returns an easily parsed response. Even though Investment Management's
intranet was the primary target it was deliberately decided not to embed HTML
into the workers:
- Plain text responses are more generic and can be used by other clients
- Plain text responses are easier for programmers (and ordinary humans) to
read.
- Plain text responses require minimal documentation
- Embedded HTML would require us to recompile and relink whenever the look
had to change.
- Formatting HTML output was not germane to what a Quotron worker should do
- Other programs format HTML better and more flexibly
- Why hardcode HTML when other standards like OFX (Open Financial eXchange)
exist?